library(rvest)
library(tidyverse)
library(magrittr)
library(stringr)
library(Rfacebook)
library(tidytext)
library(tm)Motivação para o post
Apesar de hoje em dia eu morar no Rio de Janeiro, morei e vivi (quase) a vida toda em Aracaju, a capital do menor estado do Brasil. Devido à irrelevância que a cidade tem (desculpa mas é verdade) no cenário político e econômico do país, era (e ainda é) muito raro ver qualquer notícia em um veículo de audiência nacional (como o Jornal Nacional ou a homepage do G1 ou Estadão) relacionada a Aracaju ou a Sergipe que não seja desgraça ou por um acontecimento inusitadamente ruim. Voltei a notar isso recentemente, quando saiu na homepage do G1 uma notícia de Sergipe sobre o desabamento de um camarote durante a Odonto Fantasy, uma das maiores festas a fantasia do Brasil.
Como bom entusiasta por Data Science, decidi não me ater ao senso comum de que Sergipe só tem destaque nacional por motivos de desgraça e sujei as mãos: é possível testar a hipótese de que certos temas são mais associados a algumas cidades que outras? O que destaca as notícias sobre estados menores que saem na homepage do G1 comparadas com as de estados maiores?
Consigo pensar em pelo menos dois (possivelmente existem mais) métodos para realizar essa análise: além da análise de frequência mencionada acima (a palavra X está mais associada a cidade Y1 do que a cidade Y2), poderia ser aplicada uma análise de sentimento para distinguir o sentimento de notícias relacionadas a Aracaju em comparação com o de cidades maiores. Neste post, o foco será na primeira alternativa.
Coleta dos dados
Vejam que fui enfático sobre a notícia em si ter saído na homepage do G1 ou não. Ou seja, não basta ela ter saído na página local do estado (como a de Sergipe). O primeiro problema é então ter um histórico de notícias que saíram na primeira página, o que não existe em nenhum lugar público na Internet. Não bastaria entrar na página de cada estado e coletar as notícias. Nesta análise, é fundamental ter a certeza de que pessoas de todo o Brasil puderam ter acesso fácil ao artigo.
Para resolver o problema, utilizei o pressuposto de que, se a notícia foi postada na página do G1 no Facebook, é porque ela saiu na home. Não sei o quanto que isso é verdade, mas acredito que seja uma hipótese válida.
Para extrair os links postados na página do G1 no Facebook, utilizamos o pacote Rfacebook:
token <- readRDS("/home/sillas/R/facebook_token.Rds")
g1 <- Rfacebook::getPage("180562885329138", token = token, n = 5000)O intervalo pesquisado é:
range(sort(g1$created_time))## [1] "2006-09-18T07:00:00+0000" "2017-10-14T20:46:01+0000"g1_links <- g1$linkNem todos os links postados pela página redirecionam ao G1: alguns são de vídeos postados no próprio Facebook. Por isso, é necessário limpar os dados:
# remover links de videos do facebook
g1_links <- g1_links[!str_detect(g1_links, "www.facebook.com")]
# ver links mais comuns
str_replace_all(g1_links, "http://|https://", "") %>% str_replace_all("/.*", "") %>% table()## .
## bit.ly fantastico.globo.com g1.globo.com
## 8 1 717
## glo.bo globoesporte.globo.com media.giphy.com
## 895 8 1
## s2.glbimg.com
## 1Ainda existem alguns links meio nebulosos. Vamos nos ater aos que são do G1 (g1.globo.com) e do encurtador de URLs da Globo.com (glo.bo). Para estes últimos, como precisamos extrair o estado da notícia da URL (de https://g1.globo.com/se/sergipe/noticia/camarote-desaba-durante-show-de-ivete-sangalo-em-aracaju.ghtml precisamos extrair “se”, a sigla de Sergipe), uso uma função postada no meu Gist para converter uma URL encurtada em normal:
# manter apenas links glo.bo e g1.globo.com
g1_links <- g1_links[str_detect(g1_links, "g1.globo.com|glo.bo") & !is.na(g1_links)]
# carregar funcao para transformar url encurtada
devtools::source_gist("2e92f880811f460c7edd0a622563a17a", filename = "getLongURL.R")
# converter links glo.bo para urls inteiras
ind <- str_which(g1_links, "glo.bo")
getLongURL.curl.possibly <- possibly(getLongURL.curl, otherwise = NA)
novos_links <- g1_links[ind] %>% map_chr(getLongURL.curl.possibly)
g1_links[ind] <- novos_links
# manter apenas links glo.bo e g1.globo.com (para remover links de outros sites da globo, como o Globoesporte.com)
g1_links <- g1_links[str_detect(g1_links, "g1.globo.com|glo.bo") & !is.na(g1_links)]Tendo os links corrigidos, podemos então criar uma função que extraia o corpo da notícia do link. Como o foco deste post não é o Web Scraping em si e sim os dados resultantes dele, não vou descrever muito o que a função abaixo faz. Em caso de dúvidas, escreva nos comentários do post ou entre em contato comigo que eu responderei com grande prazer.
# criar função
extrair_g1 <- function(url_g1){
# exemplo de url:
# "https://g1.globo.com/rio-de-janeiro/noticia/imagens-mostram-acao-de-criminosos-durante-assalto-na-zona-norte-do-rio.ghtml"
if (!str_detect(url_g1, "glo.bo") & !str_detect(url_g1, "g1.globo")){
warning(paste0("Link inválido: ", url_g1))
return(NA)
}
x <- url_g1 %>% read_html()
# extrair sessao da noticia
css_nome_caderno <- ".header-editoria--link"
caderno <- x %>% html_nodes(css_nome_caderno) %>% html_text()
if (length(caderno) == 0) caderno <- NA
# extrair corpo da noticia
css_corpo_a <- ".content-text__container"
css_corpo_b <- "#materia-letra p"
css_corpo_c <- ".post-content p"
corpo_noticia <- x %>%
html_nodes(css_corpo_a) %>%
html_text()
# se o css selector nao funcionou, use outro:
if (length(corpo_noticia) == 0) {
corpo_noticia <- x %>%
html_nodes(css_corpo_b) %>%
html_text()
}
if (length(corpo_noticia) == 0) {
corpo_noticia <- x %>%
html_nodes(css_corpo_c) %>%
html_text()
}
# colapsar corpo da noticia em um vetor de elemento unico
corpo_noticia <- paste0(corpo_noticia, collapse = ". ")
tibble(url = url_g1, caderno = caderno, corpo_noticia = corpo_noticia)
}# agora sim extrair dados do g1:
df_g1 <- g1_links %>% map_df(extrair_g1)# extrair caderno da url da noticia
df_g1$documento <- df_g1$url %>%
str_replace_all("https", "http") %>%
str_replace_all("http://g1.globo.com/", "") %>%
str_replace_all("/.*", "")Uma amostra mínima dos dados coletados:
str(df_g1[1,])## Classes 'tbl_df', 'tbl' and 'data.frame': 1 obs. of 4 variables:
## $ url : chr "https://g1.globo.com/politica/operacao-lava-jato/noticia/occhi-tinha-meta-mensal-de-propina-para-distribuir-a-p"| __truncated__
## $ caderno : chr "Operação Lava Jato"
## $ corpo_noticia: chr " O doleiro Lúcio Funaro afirmou em seu acordo de delação premiada com a Procuradoria Geral da República (PGR) q"| __truncated__
## $ documento : chr "politica"Agora podemos partir para a análise. Mas antes, um pouco de contexto teórico:
tf-idf
O Fator de Frequência Inversa no Documento ou term’s inverse document frequency (tf-idf) é uma técnica de mineração de texto que calcula a frequência de um determinado elemento textual (como uma palavra ou um n-gram) em um documento, diminuindo o peso de palavras comumente usadas em vários contextos diferentes (como “a”, “o” e “de”) e aumentando o peso de palavras que não são usadas em outros documentos da coleção.
No glossário de mineração de texto, documento nada mais é do que uma coleção que categoriza um conjunto de textos. Pode ser um livro (inteiro ou apenas um ou mais capítulos), a letra de uma música, um poema, uma notícia, um conjunto de notícias, etc. No nosso contexto, definimos como documento as notícias do G1 coletadas nessa amostra sobre um determinado tema, como Rio de Janeiro, São Paulo, Política ou Economia. Daí o nome da última coluna.
O livro online Text Mining with R é uma ótima referência para tf-idf, tanto teórica quanto prática.
Resultados
Quais são os documentos mais comuns?
df_g1$documento %>% table() %>% sort() %>% rev()## .
## mundo sao-paulo rio-de-janeiro
## 205 158 118
## pop-arte tecnologia economia
## 110 102 99
## politica sp ciencia-e-saude
## 95 73 60
## planeta-bizarro bemestar musica
## 37 30 29
## distrito-federal mg pr
## 28 27 26
## carros vestibular-e-educacao goias
## 24 21 21
## brasil educacao rock-in-rio
## 21 18 17
## natureza espirito-santo sc
## 17 15 13
## rs resumo-do-dia minas-gerais
## 13 13 13
## mato-grosso 11-de-setembro bahia
## 13 13 12
## vc-no-g1 parana agenda-do-dia
## 10 10 9
## pi bienal-do-livro rj
## 8 8 7
## swu pernambuco pb
## 6 6 6
## mato-grosso-do-sul loterias rn
## 6 6 5
## to rr ro
## 4 4 4
## revolta-arabe paraiba pa
## 4 4 4
## fantastico dia-das-criancas ac
## 4 4 4
## turismo-e-viagem rihanna-no-brasil platb
## 3 3 3
## justin-bieber-no-brasil e-ou-nao-e ceara
## 3 3 3
## videos se ma
## 2 2 2
## loteria ap am
## 2 2 2
## al spfw reveillon-2012
## 2 1 1
## monitor-da-violencia especial-publicitario especiais
## 1 1 1
## dia-dos-pais dia-dos-namorados concursos-e-emprego
## 1 1 1
## amazonas
## 1As sessões do G1 que mais marcam presença na homepage são, sem muita surpresa, Mundo, São Paulo e Rio de Janeiro. Você pode ter percebido que existe tanto um documento chamado “sao-paulo” como “sp”, assim como “rio-de-janeiro” e “rj”. Isso acontece porque o G1, para os maiores estados, tem sessões separadas para a capital e para o resto das cidades.
Os dois primeiros objetos de estudo são as cidades mais famosas do Brasil: Rio de Janeiro e São Paulo. O passo-a-passo da aplicação do tf-idf para essas duas cidades é descrito abaixo:
docs <- c("rio-de-janeiro", "sao-paulo")
df_filtro <- df_g1 %>%
#mutate(caderno_url = if_else(caderno %in% vetor_cadernos, "Selecionado", "Outros"))
filter(documento %in% docs)
temp <- df_filtro %>%
# separar cada palavra do corpo da notícia em uma linha diferente, sem converter para minusculo
unnest_tokens(palavra, corpo_noticia, token = "ngrams", n = 1, to_lower = FALSE) %>%
# remover as duplicatas, isto é, as palavras que aparecem mais de uma vez em uma mesma noticia
distinct(url, palavra, .keep_all = TRUE) %>%
# contar a ocorrencia de cada palavra em cada doc
count(documento, palavra) %>%
tidytext::bind_tf_idf(term_col = palavra, document_col = documento, n_col = n) %>%
# ordenar as palavras com menor tf_idf por documento
group_by(documento) %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra)))) %>%
#filtrar as 20 de maior destaque
filter(row_number() <= 20) %>%
ungroup() %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra))))
# construir grafico
temp %>%
ggplot(aes(palavra, tf_idf, fill = documento)) +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), hjust = 1.3) +
labs(x = NULL, y = "tf-idf",
title = "Termos mais frequentes associados a apenas uma das cidades",
caption = "Fonte: Mineração de texto aplicada em notícias do G1.") +
facet_wrap(~documento, ncol = 2, scales = "free") +
coord_flip()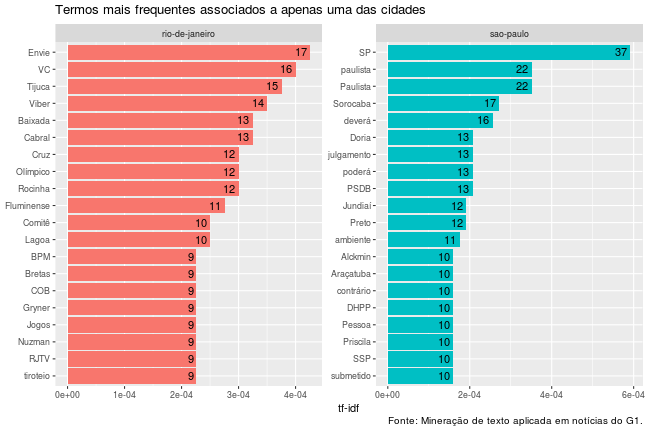
Algumas observações sobre os resultados precisam ser feitas:
- No Rio de Janeiro, aparecem alguns termos meio estranhos como Envie e VC. Isso acontece porque, durante um período, no final das reportagens, o G1 escrevia algo como “Envie VC também uma reportagem para o G1RJ pelo Whatsapp ou pelo Viber”.
- Alguns nomes próprios se destacam, o que é natural, visto que Dória é prefeito de SP e Cabral um ex-governador do RJ. Em mineração de texto, esse tipo de dado é chamado de Entidade.
Para limpar os resultados no segundo caso, são removidos os substantitos próprios. A maneira que eu bolei para isso talvez não seja a mais científica ou linguisticamente correta possível, mas aparenta ter funcionado. Ela se baseia em remover toda palavra que não é igual se escrita toda em minúsculo ou se escrita toda em maiúsculo. Por exemplo:
eh_substantivo_comum <- function(x) {x == str_to_lower(x) | x == str_to_upper(x)}
c(eh_substantivo_comum("tiroteio"), eh_substantivo_comum("RJTV"), eh_substantivo_comum("Doria"))## [1] TRUE TRUE FALSEAproveitando o embalo da limpeza de dados, os termos mencionados acima como “Envie” e “VC” também serão removidos. Aplicando esta metodologia:
temp <- df_filtro %>%
unnest_tokens(palavra, corpo_noticia, token = "ngrams", n = 1, to_lower = FALSE) %>%
# aplicar regra do substantivo comum
filter(eh_substantivo_comum(palavra)) %>%
# remover termos estranhos
filter(!palavra %in% c("VC", "RJTV")) %>%
distinct(url, palavra, .keep_all = TRUE) %>%
count(documento, palavra) %>%
tidytext::bind_tf_idf(term_col = palavra, document_col = documento, n_col = n) %>%
group_by(documento) %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra)))) %>%
filter(row_number() <= 20) %>%
ungroup() %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra))))
# construir grafico
temp %>%
ggplot(aes(palavra, tf_idf, fill = documento)) +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), hjust = 1.3) +
labs(x = NULL, y = "tf-idf",
title = "Termos mais frequentes associados a apenas uma das cidades",
caption = "Fonte: Mineração de texto aplicada em notícias do G1.") +
facet_wrap(~documento, ncol = 2, scales = "free") +
coord_flip()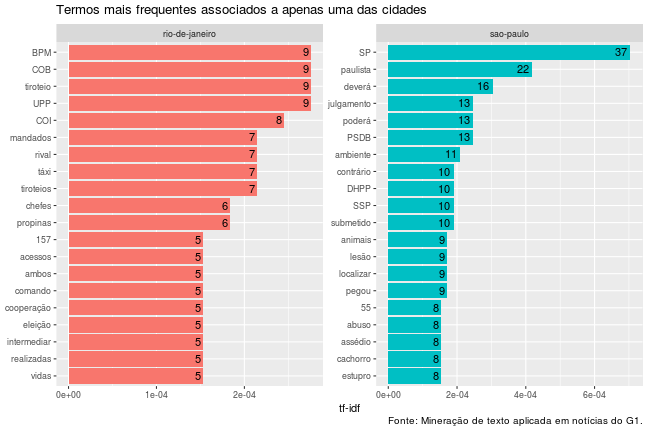
Agora é possível notar resultados mais interessantes: termos relacionados ao tráfico de drogas como tiroteio, rival, UPP e propinas possui uma frequência relativa muito maior em notícias sobre a cidade do Rio de Janeiro que na capital paulista. Por outro lado, notícias sobre estupro e abuso parecem ser mais comuns na terra onde biscoito é chamado de bolacha.
Também é possível realizar essa mesma análise por expressões compostas por mais de uma palavra, que são os chamados n-grams, onde n é a quantidade de termos. Analisando os 2-grams:
temp <- df_filtro %>%
unnest_tokens(palavra, corpo_noticia, token = "ngrams", n = 2, to_lower = FALSE) %>%
# aplicar regra do substantivo comum
filter(eh_substantivo_comum(palavra)) %>%
distinct(url, palavra, .keep_all = TRUE) %>%
count(documento, palavra) %>%
tidytext::bind_tf_idf(term_col = palavra, document_col = documento, n_col = n) %>%
group_by(documento) %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra)))) %>%
filter(row_number() <= 20) %>%
ungroup() %>%
arrange(desc(tf_idf)) %>%
mutate(palavra = factor(palavra, levels = rev(unique(palavra))))
# construir grafico
temp %>%
ggplot(aes(palavra, tf_idf, fill = documento)) +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), hjust = 1.3) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~documento, ncol = 2, scales = "free") +
coord_flip()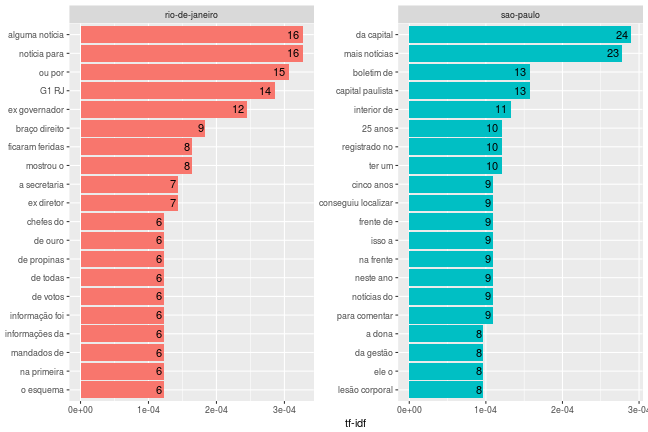
E Sergipe?
Conforme foi mostrado um pouco acima, existem apenas 2 notícias de Sergipe na amostra coletada. O Sudeste é o grande monopolizador da primeira página do G1. Mesmo se aplicássemos o tf-idf comparando o Rio de Janeiro com Sergipe, os resultados seriam enviesados devido à baixíssima quantidade de dados do último. Por isso, Norte e Nordeste são agregadas como uma:
Vamos então criar mais uma coluna para identificar a região do Brasil a qual a notícia se refere:
df_g1 %<>%
mutate(regiao = case_when(
documento %in% c("ac", "am", "amazonas", "ap", "pa", "ro", "rr") ~ "Norte",
documento %in% c ("al", "bahia", "ceara", "ma", "paraiba", "pb", "pernambuco", "pi", "rn", "se", "to") ~ "Nordeste",
documento %in% c("distrito-federal", "goias", "mato-grosso", "mato-grosso-do-sul") ~ "Centro-Oeste",
documento %in% c("espirito", "mg", "minas-gerais", "rio-de-janeiro", "rj", "sao-paulo", "sp") ~ "Sudeste",
documento %in% c("parana", "rs", "sc") ~ "Sul",
#caderno_url %in% "mundo" ~ "Mundo",
TRUE ~ NA_character_
))
df_g1$regiao[df_g1$regiao %in% c("Norte", "Nordeste")] <- "Norte-Nordeste"
# regioes mais comuns:
df_g1$regiao %>% table() %>% sort() %>% rev()## .
## Sudeste Norte-Nordeste Centro-Oeste Sul
## 396 75 68 36Para não ter de repetir o código que constrói os gráficos acima, salvei a função neste Gist, com direito a algumas parametrizações, como a opção de remover ou não substantivos próprios:
id_gist <- "2d626f33ee1b635a0aa3beeda31ae720"
devtools::source_gist(id_gist, filename = "grafico_g1.R")
df_g1 %>%
mutate(documento = regiao) %>%
filter(!is.na(documento)) %>%
grafico_tfidf(n_grams = 1, remover_nomes_proprios = TRUE, agregar_por_noticia = TRUE)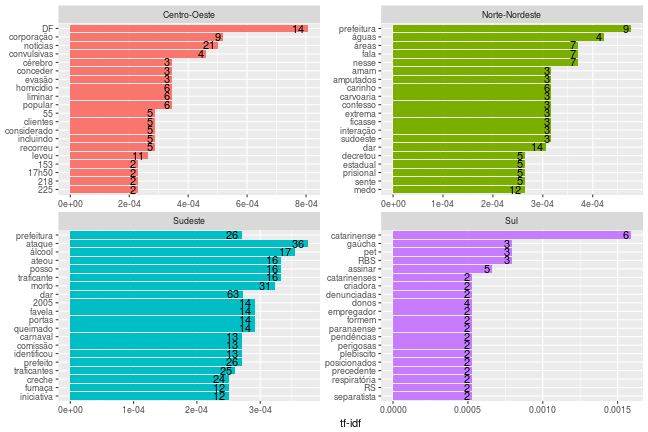
Mesmo agregando os dados por região, o desbalanceamento da quantidade de notícias por região prejudicou os resultados. Seria necessário coletar muito mais notícias para que os resultados fossem mais interessantes.
Bônus
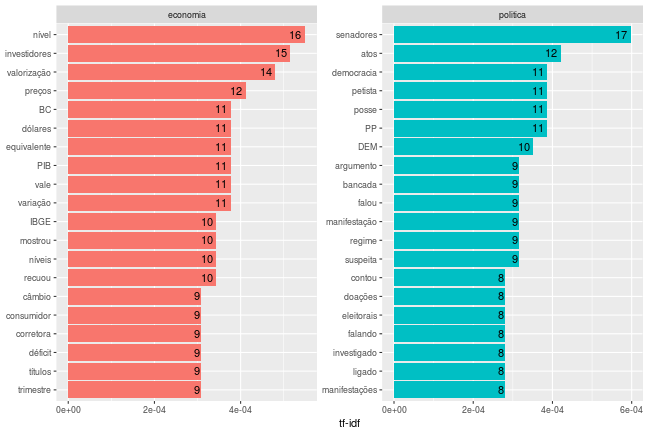
A análise não precisa se restringir a regiões demográficas. Podemos, por exemplo, comparar notícias dos cadernos de Política e Economia:
df_g1 %>%
filter(documento %in% c("politica", "economia")) %>%
grafico_tfidf(n_grams = 1, remover_nomes_proprios = TRUE, agregar_por_noticia = TRUE)