De volta à ativa no blog!
Recentemente, quando precisei fazer pela primeira vez algum tipo de análise em cima de textos (o chamado Text Mining ou Mineração de Texto) em Português, senti falta de ter um acesso fácil a um léxico na linguagem. O R já tem a sua disposição vários recursos para quem quer fazer Text Mining em inglês, como os pacotes tokenizer, tidytext, tm e lexicon, além de vários blog posts sobre Sentiment Analysis que você encontra no R-bloggers. Contudo, existe uma séria escassez de material de referência na língua portuguesa.
O pacote lexiconPT, que eu lancei em 20/09/2017 no Github (e em breve no CRAN também) nasceu para resolver parte desse problema. Até o momento, o lexiconPT possui três datasets de léxicos: o OpLexicon (versões 2.1 e 3.0) e o SentiLex-PT02. Não pretendo (nem tenho competência para tal, pois sou iniciante em Text Mining - sem falsa modéstia) destrinchar como cada um deles funciona e em quê eles diferem. Para isso, sugiro ler as referências citadas na documentação dos próprios datasets (ex.: help("oplexicon_v2.1")).
Mas ter o léxico em mãos só resolve parte dos problemas: ainda faltam os textos em si para serem analisados. Algumas ideias de datasets poderiam ser notícias, letras de músicas, livros (tem vários em Domínio Público), tweets, etc. Para demonstrar um simples uso do pacote, eu decidi por analisar comentários feitos por usuários na página do Sensacionalista, uma das mais populares do Facebook. A coleta dos dados foi relativamente fácil graças ao pacote Rfacebook.
Com o pacote lexiconPT, podemos responder a perguntas como:
- Os comentários no Sensacionalista são mais negativos ou positivos?
- Qual termo está mais associado a comentários negativos? PT ou PSDB? Temer ou Dilma? Bolsonaro ou Lula?
- Qual o comentário feito por um usuário mais negativo da história do Sensacionalista (dentro da amostra coletada)? E qual o mais positivo?
Vamos ao código.
Coleta dos dados
library(Rfacebook) # usado para extrair dados do facebook
library(tidyverse) # pq nao da pra viver sem
library(ggExtra)
library(magrittr) # <3
library(lubridate)
library(stringr) # essencial para trabalhar com textos
library(tidytext) # um dos melhores pacotes para text mining
library(lexiconPT)Este post só foi possível graças ao Rfacebook. Para aprender como ele funciona, leia a documentação presente em seu repo no Github. Para este primeiro, primeiro usei a função getPage() para extrair as últimas 5000 publicações do Sensacionalista.
# token que eu gerei com minha API key.
# Essa parte vc obviamente nao vai conseguir reproduzir.
# leia o README do Rfacebook para saber como obter seu token
fb_token <- readRDS("/home/sillas/R/data/facebook_token.Rds")
# demora cerca de 10 min pra rodar:
pg <- getPage("sensacionalista", fb_token, n = 5000)É necessário corrigir o encoding do corpo da publicação para o R parar de reclamar sobre isso:
# corrigir encoding do texto do post
pg$message %<>% iconv(to = "ASCII//TRANSLIT")
# remover emojis
pg$message %<>% iconv(sub="", 'UTF-8', 'ASCII')
# visualizar dataframe
glimpse(pg)## Observations: 4,666
## Variables: 11
## $ from_id <chr> "108175739225302", "108175739225302", "10817573...
## $ from_name <chr> "Sensacionalista", "Sensacionalista", "Sensacio...
## $ message <chr> "Apos liminar da Justica do DF permitir o trata...
## $ created_time <chr> "2017-09-18T18:58:53+0000", "2017-09-18T17:25:0...
## $ type <chr> "link", "link", "link", "link", "video", "link"...
## $ link <chr> "http://www.sensacionalista.com.br/2017/09/18/l...
## $ id <chr> "108175739225302_1638598099516384", "1081757392...
## $ story <chr> NA, NA, NA, NA, "Sensacionalista shared Gshow -...
## $ likes_count <dbl> 10172, 2162, 2503, 5793, 4676, 2585, 821, 766, ...
## $ comments_count <dbl> 230, 164, 285, 221, 329, 104, 32, 58, 493, 586,...
## $ shares_count <dbl> 2290, 453, 410, 2751, 0, 930, 26, 36, 900, 92, ...Só esse dataset por si só já renderia (e renderá) análises interessantes, mas vou as deixar para um futuro post para não deixar este aqui grande demais.
A coluna id é a que usaremos como referência como input na função getPost() para extrair os comentários dos usuários na publicação. Infelizmente, a API do Facebook apresenta uma certa instabilidade para requests de dados muito grandes. Em várias tentativas que fiz, o máximo de dados que consegui extrair foram 200 comentários de 500 publicações da página. Portanto, vou usar esses parâmetros:
# roda em cerca de 8 minutos:
df_posts <- pg$id[1:500] %>% map(getPost, fb_token, n = 200, comments = TRUE, likes = FALSE,
reactions = FALSE)A função getPost() fornece o seguinte output:
str(df_posts)## List of 500
## $ :List of 2
## ..$ post :'data.frame': 1 obs. of 10 variables:
## .. ..$ from_id : chr "108175739225302"
## .. ..$ from_name : chr "Sensacionalista"
## .. ..$ message : chr "Após liminar da Justiça do DF permitir o tratamento da homossexualidade como doença"
## .. ..$ created_time : chr "2017-09-18T18:58:53+0000"
## .. ..$ type : chr "link"
## .. ..$ link : chr "http://www.sensacionalista.com.br/2017/09/18/liminar-que-chancela-cura-gay-permite-tratar-justica-brasileira-como-doenca/"
## .. ..$ id : chr "108175739225302_1638598099516384"
## .. ..$ likes_count : num 11340
## .. ..$ comments_count: num 248
## .. ..$ shares_count : num 2590
## ..$ comments:'data.frame': 200 obs. of 7 variables:
## .. ..$ from_id : chr [1:200] "1437254732976789" "1445900342154501" "10209941046899919" "173469923210786" ...
## .. ..$ from_name : chr [1:200] "Sérgio Henrique Reis" "Renata Gil" "Lucas Ferreira" "Leonardo Wesley" ...
## .. ..$ message :## Error in strtrim(encodeString(object, quote = "\"", na.encode = FALSE), : string multibyte inválida em '<a0><be>\xed'Para extrair os dataframes relativos aos comentários e aos metadados das publicações, o purrr é uma mão na roda:
df_comments <- df_posts %>% map_df("comments")
df_posts <- df_posts %>% map_df("post")
# repetir procedimento de consertar o encoding
df_comments$message %<>% iconv(to = "ASCII//TRANSLIT") %>% iconv(sub="", 'UTF-8', 'ASCII')
df_posts$message %<>% iconv(to = "ASCII//TRANSLIT") %>% iconv(sub="", 'UTF-8', 'ASCII')
# por questoes de anonimizacao, vou remover os dados pessoais referentes aos usuarios
df_comments %<>% select(-from_id, -from_name)
# olhar estrutura dos dataframes
str(df_comments)## 'data.frame': 72100 obs. of 5 variables:
## $ message : chr "Entao pode faltar no servico, ligar pro chefe(a), levar atestado e dizer que acordou com vontade de chupar rola?" "Nunca o sensacionalista foi tao verdadeiro. Pq a justica brasileira se demonstrou uma verdadeira praga na socie"| __truncated__ "O unico que precisa de tratamento e o sr juiz que autorizou." "Isso viola todas os acordos internacionais e uma aberracao contra qqr liberdade individual e humana. Logo essa liminar cai." ...
## $ created_time : chr "2017-09-18T19:01:21+0000" "2017-09-18T19:03:57+0000" "2017-09-18T19:01:26+0000" "2017-09-18T19:00:54+0000" ...
## $ likes_count : num 575 392 270 227 310 145 113 73 38 50 ...
## $ comments_count: num 58 5 4 3 12 16 10 0 0 8 ...
## $ id : chr "1638598099516384_1638600206182840" "1638598099516384_1638602159515978" "1638598099516384_1638600266182834" "1638598099516384_1638599869516207" ...str(df_posts)## 'data.frame': 500 obs. of 10 variables:
## $ from_id : chr "108175739225302" "108175739225302" "108175739225302" "108175739225302" ...
## $ from_name : chr "Sensacionalista" "Sensacionalista" "Sensacionalista" "Sensacionalista" ...
## $ message : chr "Apos liminar da Justica do DF permitir o tratamento da homossexualidade como doenca" "Ja recebeu encomendas de quarteis" "Aparelho esta sendo oferecido por importadores por ate 6 mil reais" "Temer desembarcou nos Estados Unidos para jantar com Trump e participacao na Assembleia Geral da ONU" ...
## $ created_time : chr "2017-09-18T18:58:53+0000" "2017-09-18T17:25:00+0000" "2017-09-18T17:05:41+0000" "2017-09-18T17:00:02+0000" ...
## $ type : chr "link" "link" "link" "link" ...
## $ link : chr "http://www.sensacionalista.com.br/2017/09/18/liminar-que-chancela-cura-gay-permite-tratar-justica-brasileira-como-doenca/" "http://www.sensacionalista.com.br/2017/09/18/fabricante-de-pau-de-arara-comemora-falta-de-resposta-a-general-qu"| __truncated__ "http://www.sensacionalista.com.br/2017/09/18/empresa-lanca-servico-de-escolta-armada-para-quem-comprar-o-iphone-x/" "http://www.sensacionalista.com.br/2017/09/18/coreia-do-norte-nega-ter-lancado-temer-nos-eua/" ...
## $ id : chr "108175739225302_1638598099516384" "108175739225302_1638510679525126" "108175739225302_1638503796192481" "108175739225302_1638456466197214" ...
## $ likes_count : num 11340 2271 2826 6361 4990 ...
## $ comments_count: num 248 167 315 242 347 106 32 58 494 590 ...
## $ shares_count : num 2590 478 441 3008 0 ...Só pode ser trollagem da API do Facebook retornar aquela mensagem logo no topo do dataframe, mas enfim.
O dataframe df_comments, o objeto da nossa análise, não possui alguns dados que serão valiosos para a análise, como o link para o artigo no site do Sensacionalista. Por isso, vamos um left_join com o df_posts.
Percebeu que nas colunas df_comments$id e df_posts$id existe um traço separando dois conjuntos numéricos? Por alguma razão que beira a imbecilidade, não é possível combinar imediatamente essas duas colunas para formatar um dataframe só com o left_join. A sintaxe de identificação do Facebook funciona assim: O post é identificado IDPAGINA_IDPUBLICAÇÃO e o comentário na publicação é identificado como IDPUBLICAÇÃO_IDCOMENTÁRIO. Ou seja, para poder juntar os dois dataframes, vamos ter que combinar a sequência númerica à esquerda do underline (acho que esse traço tem algum outro nome, mas não me lembro no momento) em df_comments$id e à direita em df_posts$id.
# consertar colunas de id: no df_comments, deixar à esquerda do underline. no df_posts, deixar à direita.
df_comments$id_post_real <- df_comments$id
df_comments$id %<>% str_replace_all("_.*", "")
df_posts$id %<>% str_replace_all(".*_", "")
# juntar as duas tabelas
df_posts %<>% dplyr::select(id, post_message = message, horario_post = created_time,
type, post_comments_count = comments_count, post_link = link,
post_type = type, post_likes_count = likes_count)
df_comments %<>% rename(horario_comentario = created_time)
df_comments %<>% left_join(df_posts, by = "id")
# remover NAs (nao sao muitos casos)
df_comments %<>% filter(!is.na(horario_post))
# converter colunas de horario
df_comments$horario_comentario %<>% str_sub(1, 19) %>% str_replace_all("T", "") %>% ymd_hms()
df_comments$horario_post %<>% str_sub(1, 19) %>% str_replace_all("T", "") %>% ymd_hms()
# Como ficou:
glimpse(df_comments)## Observations: 71,891
## Variables: 12
## $ message <chr> "Entao pode faltar no servico, ligar pro c...
## $ horario_comentario <dttm> 2017-09-18 19:01:21, 2017-09-18 19:03:57,...
## $ likes_count <dbl> 575, 392, 270, 227, 310, 145, 113, 73, 38,...
## $ comments_count <dbl> 58, 5, 4, 3, 12, 16, 10, 0, 0, 8, 69, 3, 0...
## $ id <chr> "1638598099516384", "1638598099516384", "1...
## $ id_post_real <chr> "1638598099516384_1638600206182840", "1638...
## $ post_message <chr> "Apos liminar da Justica do DF permitir o ...
## $ horario_post <dttm> 2017-09-18 18:58:53, 2017-09-18 18:58:53,...
## $ post_type <chr> "link", "link", "link", "link", "link", "l...
## $ post_comments_count <dbl> 248, 248, 248, 248, 248, 248, 248, 248, 24...
## $ post_link <chr> "http://www.sensacionalista.com.br/2017/09...
## $ post_likes_count <dbl> 11340, 11340, 11340, 11340, 11340, 11340, ...Uso do lexiconPT
Agora temos o dataset em mãos para usar o lexiconPT. Acho muito importante ressaltar que Text Mining é uma atividade razoavelmente complexa que envolve uma extensa etapa de limpeza e tratamento de dados, como remover (ou não) acentos e corrigir palavras com letras duplicadas (tristee) ou erros gramaticais (infelismente). Para fins de simplicidade, não vou me ater muito a esses detalhes e pular direto para a utilização dos léxicos portugueses e apresentação dos resultados.
# carregar datasets
data("oplexicon_v3.0")
data("sentiLex_lem_PT02")
op30 <- oplexicon_v3.0
sent <- sentiLex_lem_PT02
glimpse(op30)## Observations: 32,191
## Variables: 4
## $ term <chr> "=[", "=@", "=p", "=P", "=x", "=d", "=D", ";...
## $ type <chr> "emot", "emot", "emot", "emot", "emot", "emo...
## $ polarity <int> -1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, ...
## $ polarity_revision <chr> "A", "A", "A", "A", "A", "A", "A", "A", "A",...glimpse(sent)## Observations: 7,014
## Variables: 5
## $ term <chr> "à-vontade", "abafado", "abafante", "a...
## $ grammar_category <chr> "N", "Adj", "Adj", "Adj", "Adj", "Adj"...
## $ polarity <dbl> 1, -1, -1, -1, -1, 1, -1, 1, 1, -1, -1...
## $ polarity_target <chr> "N0", "N0", "N0", "N0", "N0", "N0", "N...
## $ polarity_classification <chr> "MAN", "JALC", "MAN", "JALC", "JALC", ...Ambos os datasets possuem colunas de polaridade de sentimento, que é a que usaremos para quantificar o quão negativo ou positivo é um comentário.
# criar ID unica para cada comentario
df_comments %<>% mutate(comment_id = row_number())
# usar funçao do tidytext para criar uma linha para cada palavra de um comentario
df_comments_unnested <- df_comments %>% unnest_tokens(term, message)
df_comments_unnested %>%
select(comment_id, term) %>%
head(20)## comment_id term
## 1 1 entao
## 1.1 1 pode
## 1.2 1 faltar
## 1.3 1 no
## 1.4 1 servico
## 1.5 1 ligar
## 1.6 1 pro
## 1.7 1 chefe
## 1.8 1 a
## 1.9 1 levar
## 1.10 1 atestado
## 1.11 1 e
## 1.12 1 dizer
## 1.13 1 que
## 1.14 1 acordou
## 1.15 1 com
## 1.16 1 vontade
## 1.17 1 de
## 1.18 1 chupar
## 1.19 1 rola*De novo esse comentário… *
Enfim, veja que foi criada uma linha para cada palavra presetnte no comentário. Será essa nova coluna term que usaremos como referência para quantificar o sentimento de um comentário.
df_comments_unnested %>%
left_join(op30, by = "term") %>%
left_join(sent %>% select(term, lex_polarity = polarity), by = "term") %>%
select(comment_id, term, polarity, lex_polarity) %>%
head(10)## comment_id term polarity lex_polarity
## 1 1 entao NA NA
## 2 1 pode NA NA
## 3 1 faltar 1 NA
## 4 1 no NA NA
## 5 1 servico NA NA
## 6 1 ligar -1 NA
## 7 1 pro NA NA
## 8 1 chefe NA NA
## 9 1 a NA NA
## 10 1 levar -1 NAA amostra acima mostra que nem toads as palavras possuem uma polaridade registrada nos léxicos. Não só isso, mas algumas palavras (como faltar, ligar e levar) estão presentes no OpLexicon mas não no SentiLex. A polaridade 1 em faltar significa que, de acordo com esse léxico, a palavra está associada a comentários positivos. Saber essa diferença é fundamental, pois a escolha do léxico pode ter uma grande influência nos resultados da análise.
Vamos então manter no dataframe apenas as palavras que possuem polaridade tanto no OpLexicon como no SentiLex:
df_comments_unnested <- df_comments_unnested %>%
inner_join(op30, by = "term") %>%
inner_join(sent %>% select(term, lex_polarity = polarity), by = "term") %>%
group_by(comment_id) %>%
summarise(
comment_sentiment_op = sum(polarity),
comment_sentiment_lex = sum(lex_polarity),
n_words = n()
) %>%
ungroup() %>%
rowwise() %>%
mutate(
most_neg = min(comment_sentiment_lex, comment_sentiment_op),
most_pos = max(comment_sentiment_lex, comment_sentiment_op)
)
head(df_comments_unnested)## # A tibble: 6 x 6
## comment_id comment_sentiment_op comment_sentiment_lex n_words most_neg
## <int> <int> <dbl> <int> <dbl>
## 1 2 0 0 2 0
## 2 7 -2 -3 3 -3
## 3 8 1 1 2 1
## 4 9 0 0 3 0
## 5 11 -2 -2 2 -2
## 6 12 -2 -2 2 -2
## # ... with 1 more variables: most_pos <dbl>Apresentação dos resultados
O gráfico de pontos abaixo mostra a distribuição de polaridade para cada léxico:
p <- df_comments_unnested %>%
ggplot(aes(x = comment_sentiment_op, y = comment_sentiment_lex)) +
geom_point(aes(color = n_words)) +
scale_color_continuous(low = "green", high = "red") +
labs(x = "Polaridade no OpLexicon", y = "Polaridade no SentiLex") +
#geom_smooth(method = "lm") +
geom_vline(xintercept = 0, linetype = "dashed") +
geom_hline(yintercept = 0, linetype = "dashed")
p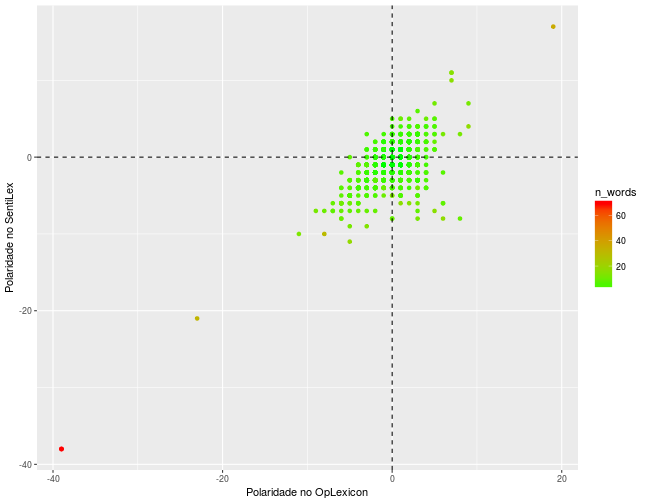
Existem pelo menos três outliers nos dados, todos causados pela grande quantidade de palavras do comentário, o que pode ser um indício de que simplesmente somar a polaridade de cada palavra do comentário pode não ser um bom método. Outra informação revelada pelo gráfico é que existem palavras que possuem sentimentos diferentes de acordo com o léxico usado. Ter isso em mente é fundamental para a análise.
Após remover os outliers, já é possível descobrir quais os comentários mais positivos e mais negativos da amostra coletada:
df_comments_unnested %<>% filter(between(comment_sentiment_op, -10, 10))
# comentario mais positivo da historia do sensacionalista
most_pos <- which.max(df_comments_unnested$most_pos)
most_neg <- which.min(df_comments_unnested$most_neg)
# mais positivo
cat(df_comments$message[df_comments$comment_id == df_comments_unnested$comment_id[most_pos]])## O mundo a esquerda e sempre melhor. A musica, o pincel, a pena e a talha. Sempre esteve para a esquerda. As grandes mentes criativas, os grandes pensadores, os humanistas, os geniais. Tudo que e original e belo e oriundo da esquerda.
## E tendencia natural do ser humano, ao passo q alcanca um minimo de consciencia critica do mundo sempre tender a esquerda.
## Todavia o mundo tambem precisa de mentes computacionais, a esse papel a direita tem seu valor. A direita funciona bem quando o objetivo e produzir o fisico, o tangivel e operacional. Embora isso tambem pudesse ser feito por maquinas, robos, ou mesmo por animais adestrados.
## A exemplo, os EUA, onde o cidadao comum e um ser vegetativo, destinado a operar, produzir e consumir. Sao seres incapazes de formular um pensamento critico e original. Uma nacao que por forca do capital tem seu vies ideologico voltado pra direita. Ainda q por vezes elejam um presidente com vies de esquerda, nunca irao evoluir sua consciencia. Sera sempre uma nacao de dementes e ignorantes.
## Nao por acaso que o capital, na sua forma economica ou politica sempre se poe sobre a direita quando tem por objetivo o ganho, financeiro ou de poder. E sobre a direita q se faz os movimentos de massa imbecilizada, pois como seres roboticos sao facilmente levados aonde se quer levar.
## A esquerda liga-se ao mundo das ideias, ao pensamento critico, a modelagem do ser humano como ser consciente. A esquerda e a construcao do pensamento, e o
## individuo pensante e critico, tudo que evolui e eleva o ser humano a um patamar de consciencia superior, provem da esquerda.
## Nacoes capitalistas, ainda q direitista, mas q sua massa possui em sua construcao um vies ideologico de esquerda serao sempre nacoes ricas financeiramente e ricas de estado de consciencia critica. Observa se isto em paises europeus, onde o
## capital existe por forca do consumo, mas coexiste com o estado de bem estar social, com a beleza das artes e com tudo aquilo e natural da esquerda, enquanto consciencia e beleza.
## A direita tem por tendencia natural, o simples, o computacional e robotizado. O argumento da direita e sempre algoritmo, linear e raso. A direita sera sempre um universo de seres ocos, massivos e imbecilizados.
## A.L.C.# mais negativo
cat(df_comments$message[df_comments$comment_id == df_comments_unnested$comment_id[most_neg]])## Ditadura Comunista
##
## Em pleno 2017 hoje o Brasil debate o tema comunismo, pare estranho falar uma coisa dessa mais e isso que gerou esse grande populismo do Jair Bolsonaro. O Jair Bolsonaro criou um inimigo da sociedade um inimigo do Brasil que e o comunismo e hoje ele bate em cima dessa ideia de comunismo mais agente pensa a Uniao das Republicas Socialistas Sovieticas deixou de ser comunista sera que o Brasil vai querer ser hoje comunista, sera que alguem ja viu algum partido do Brasil nos ultimos 40 anos viu algum partido do Brasil tentar implementar comunismo no Brasil. O comunismo e um regime onde ninguem tem propriedade o estado tem tudo sera que um politico de hoje em dia gostaria de perder tudo que tem para poder implementar um comunismo eu acredito que nao exista no Brasil inclusive o PSDB que e um partido comunista do Brasil, eu acredito que eles nao tem ideologias de implementacao do comunismo, entao quando a gente tem um partido de esquerda e um partido onde tem aquela ideia que reverter o dinheiro do rico para o pobre atraves de educacao, saude ou ate mesmo a bolsa familia eles chama isso de comunismo, mais na hora que eles agridem a ideologia comunista eles falam do comunismo radical aquele comunismo de tomar tudo das pessoas e entregar para o estado isso mostra que existe realmente uma carencia de educacao na juventude brasileira que e a maioria dessas pessoas que estao defendendo o Bolsonaro, elas realmente acreditam nessa historia de que um partido brasileiro vai implementar um ditadura e vai implementar o comunismo no Brasil.
## So que a coisa e muito controversia porque eles acreditam que as forcas armadas sao integras agora eu pergunto e chamo para uma reflexao. Existe a possibilidade de um presidente de um estado que era democratico hoje e ditadura mais era democratico vamos pensar eles acusam o Lula de tentar implementar o comunismo, existe a possibilidade de um presidente em um pais que eles consideram as forcas armadas integra implementar um comunismo? Entao nao tem como o presidente implementar o comunismo sem a ajuda das forcas armadas ai a gente ve que tem uma discrepancia muito forte da informacao e essas lacunas de informacao que sao os caminhos para educar essa molecada que esta com esse tipo de ideia, realmente foi despertado um medo muito grande do comunismo por mais que parece estranho mesma coisa de falar para criancas terem medo do lobo mal hoje em dia parece absurdo pra quem e adulto mais eles estao com medo do comunismo. E esse tipo de dialogo e esse tipo de conversa que esta criando essa massa de jovens eleitores do Bolsonaro o medo do comunismo.Por incrível que pareça, tanto o comentário mais positivo quanto o mais negativo falam sobre a esquerda.
Para prosseguir com a análise, usaremos o léxico OpLexicon para a análise de sentimento:
df_comments %<>% inner_join(
df_comments_unnested %>% select(comment_id, sentiment = comment_sentiment_op),
by = "comment_id"
)
# criar coluna de data (variavel da classe Date)
df_comments$data <- as.Date(df_comments$horario_post)Agora sim podemos demonstrar uma visualização de uma análise básica de sentimento: Como tem sido o sentimento geral dos comentários no Sensacionalista ao longo do tempo?
df_comments_wide <- df_comments %>%
# filtrar fora palavras neutras
filter(sentiment != 0) %>%
# converter numerico para categorico
mutate(sentiment = ifelse(sentiment < 0, "negativo", "positivo")) %>%
# agrupar os dados
count(data, post_link, post_type, sentiment) %>%
# converter para formato wide
spread(sentiment, n, fill = 0) %>%
mutate(sentimento = positivo - negativo) %>%
ungroup() %>%
arrange(data)
head(df_comments_wide) %>% knitr::kable()| data | post_link | post_type | negativo | positivo | sentimento |
|---|---|---|---|---|---|
| 2017-04-13 | https://www.facebook.com/sensacionalista/photos/a.187587037950838.39557.108175739225302/1460990897277106/?type=3 | photo | 9 | 13 | 4 |
| 2017-04-13 | http://www.sensacionalista.com.br/2017/04/13/temer-lula-e-fhc-articulam-pacto-de-nao-rir-de-brasileiro-que-desfez-amizade-no-facebook-por-politica/ | link | 31 | 24 | -7 |
| 2017-04-14 | https://www.facebook.com/sensacionalista/photos/a.187587037950838.39557.108175739225302/1462221330487396/?type=3 | photo | 42 | 9 | -33 |
| 2017-04-15 | https://www.facebook.com/sensacionalista/photos/a.187587037950838.39557.108175739225302/1463589740350555/?type=3 | photo | 5 | 8 | 3 |
| 2017-04-16 | https://www.sensacionalista.com.br/2016/03/25/laja-jato-diz-que-lula-comprou-ovo-da-kopenhagen-em-nome-de-amigo/ | link | 19 | 27 | 8 |
| 2017-04-16 | http://www.sensacionalista.com.br/2017/04/10/as-18-melhores-coisas-com-sentimentos-a-nova-obsessao-da-internet/ | link | 17 | 14 | -3 |
Por exemplo, o primeiro link coletado na amostra, uma foto, teve 9 palavras contadas como negativas e 13 como positivas. O score geral dos comentários nessa publicação foi 13 - 9 = 4.
Qual a publicação do Sensacionalista com maior nível de “positividade”? E o de “negatividade”?
df_comments_wide %>%
arrange(sentimento) %>%
filter(row_number() == 1 | row_number() == nrow(df_comments_wide)) %>%
knitr::kable()| data | post_link | post_type | negativo | positivo | sentimento |
|---|---|---|---|---|---|
| 2017-09-11 | http://www.sensacionalista.com.br/2017/09/11/projeto-do-mbl-pretende-vestir-obras-de-arte-em-museus-ao-redor-do-mundo/ | link | 90 | 28 | -62 |
| 2017-06-05 | http://www.sensacionalista.com.br/2017/06/05/festa-se-nada-der-certo-em-colegio-debocha-de-garis-e-faxineiras-e-mostra-que-ja-deu-tudo-errado/ | link | 33 | 84 | 51 |
A publicação que mais recebeu comentários negativos (não tenho certeza se é essa a interpretação mais correta dos resultados, mas enfim) é um link sobre o MBL, enquanto o mais positivo é sobre o famoso caso do “E se der errado”.
O gráfico abaixo mostra a evolução do sentimento dos comentários nas publicações do Sensacionalista ao longo do tempo:
df_comments_wide %>%
mutate(index = row_number()) %>%
ggplot(aes(x = index, y = sentimento)) +
geom_col(aes(fill = post_type)) +
scale_y_continuous(breaks = seq(-60, 60, 20), limits = c(-60, 60)) +
labs(x = "Índice da publicação", y = "Sentimento",
fill = NULL, title = "Evolução do sentimento em publicações do Sensacionalista")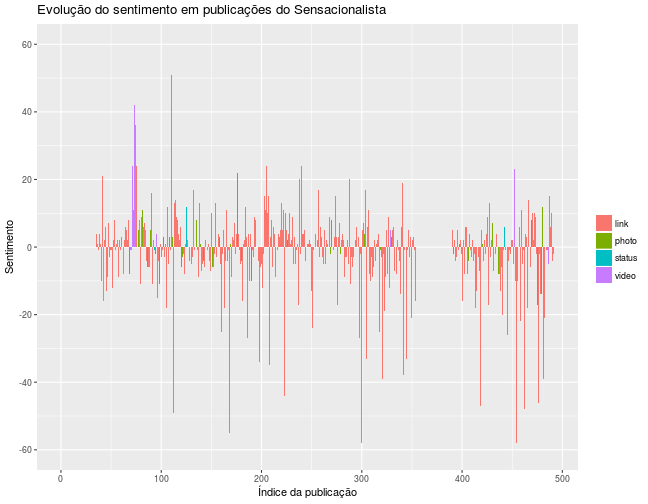
Uma possível interpretação do gráfico é que a série temporal não possui uma clara tendência, apesar de os picos de negatividade serem bem mais frequentes que os de positividade.
Outra análise que dá para fazer é investigar o nível de sentimento de comentários associados a determinadas palavras. Por exemplo, o quão negativo costuma ser um comentário quando ele menciona a palavra bolsonaro?
# qual o sentimento mais associado a palavras em especifico
df_comments %>%
mutate(
temer = str_detect(str_to_lower(message), "temer"),
lula = str_detect(str_to_lower(message), "lula"),
pmdb = str_detect(str_to_lower(message), "pmdb"),
psdb = str_detect(str_to_lower(message), "psdb"),
pt = str_detect(str_to_lower(message), "pt"),
dilma = str_detect(str_to_lower(message), "dilma"),
doria = str_detect(str_to_lower(message), "doria"),
governo = str_detect(str_to_lower(message), "governo"),
bolsonaro = str_detect(str_to_lower(message), "bolsonaro")
) %>%
gather(termo, eh_presente, temer:bolsonaro) %>%
filter(eh_presente) %>%
group_by(termo) %>%
summarise(sentiment = mean(sentiment)) %>%
ggplot(aes(x = termo, y = sentiment)) +
geom_col(fill = "#C10534")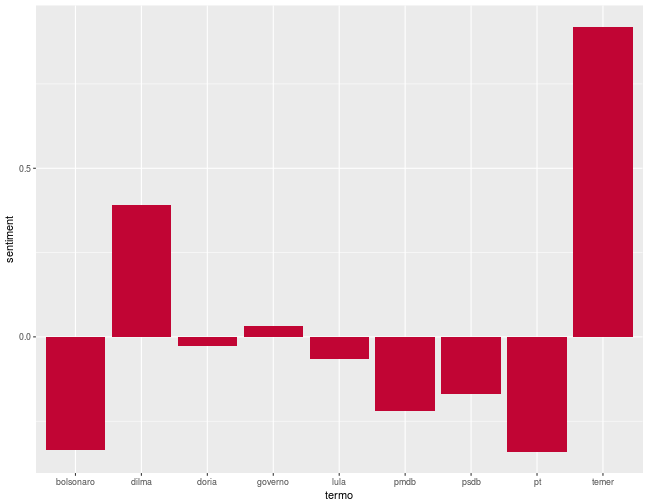
Temer e Dilma, os dois presidentes com os piores níveis de popularidade de República, estarem associados a comentários positivos é bem surpreendente. Na verdade, isso ocorre porque a própria palavra temer possui polaridade positiva. Para consultar a polaridade de uma palavra nos datasets presentes no lexiconPT, use a função lexiconPT::get_word_sentiment().
get_word_sentiment("temer")## $oplexicon_v2.1
## term type polarity
## 28711 temer vb 1
##
## $oplexicon_v3.0
## term type polarity polarity_revision
## 30160 temer vb 1 A
##
## $sentilex
## term grammar_category polarity polarity_target
## 6546 temer V -1 N0:N1
## polarity_classification
## 6546 MANConclusão e chamada para futuros trabalhos
O pacote lexiconPT, apesar de simples, tem um enorme potencial para enriquecer o conteúdo de Text Mining em Português na comunidade brasileira de R. O exemplo dado nesse post pode ser considerado deveras simplório. Muitas etapas foram puladas ou desconsideradas com o intuito de fornecer a você uma rápida introdução às possibilidades criadas pelo pacote. Espero que o leitor deste post tenha se sentido motivado a fazer suas próprias análises de sentimento. As possibilidade são incontáveis.
Referências
- Text Mining with R - A Tidy Approach: Livro online gratuito sobre Text Mining feito pela autora do pacote
tidytext; - Single Word Analysis of Early 19th Century Poetry Using tidytext;
- Texto no R;
- A Fixação de Colbert ;
- Mineração de Texto - Prof. Walmes M. Zeviani;
- Pacote tidytext;
- Text Mining of Stack Overflow Questions;
- Women in film