Transparência (5): Trabalhando com datas
O dataset do Portal da Transparência traz três colunas relacionadas com datas: DATA_INGRESSO_CARGOFUNCAO, DATA_INGRESSO_ORGAO e DATA_DIPLOMA_INGRESSO_SERVICOPUBLICO, as quais geram umas análises curiosas, principalmente se relacionadas com a variável salário.
library(treemap)
library(dplyr)
library(ggplot2)
library(ggrepel)
library(ggthemes)
library(lubridate)
df <- read.csv2("/home/sillas/R/data/transparenciaComSalarios.csv", stringsAsFactors = FALSE, fileEncoding = "ISO-8859-15")Primeiro, as datas vêm neste formato:
df %>%
select(DATA_INGRESSO_CARGOFUNCAO, DATA_INGRESSO_ORGAO, DATA_DIPLOMA_INGRESSO_SERVICOPUBLICO) %>%
head()## DATA_INGRESSO_CARGOFUNCAO DATA_INGRESSO_ORGAO
## 1 01/07/2006 01/01/1984
## 2 22/10/2014 20/10/2014
## 3 <NA> 01/08/2015
## 4 30/11/2014 03/09/2014
## 5 19/05/2010 19/05/2010
## 6 02/02/2009 30/12/2008
## DATA_DIPLOMA_INGRESSO_SERVICOPUBLICO
## 1 01/06/1984
## 2 17/02/2010
## 3 01/08/2015
## 4 28/06/2006
## 5 19/05/2010
## 6 30/12/2008O R, nativamente, não reconhece este formato como data e sim como texto. O formato de datas que o R aceita é o americano, YYYYMMDD. Felizmente, o package lubridate torna muito fácil converter as datas:
df <- df %>%
mutate(dataCargo = dmy(DATA_INGRESSO_CARGOFUNCAO),
dataOrgao = dmy(DATA_INGRESSO_ORGAO),
dataServico = dmy(DATA_DIPLOMA_INGRESSO_SERVICOPUBLICO))Essas três variáveis nos dão o dia em que os servidores começaram a trabalhar. Para termos a quantidade de tempo que se passou desde então, criei duas funções que fazem esse cálculo:
CalcMeses <- function(t0, t=today()) {
x <- interval(t0, t)
x <- as.period(x)
x <- year(x)*12 + month(x)
return(x)
}
CalcAnos <- function(t0, t=today()) {
x <- interval(t0, t)
x <- as.period(x)
x <- ceiling(year(x) + month(x)/12)
return(x)
}
df$meses.no.cargo <- CalcMeses(df$dataCargo)
df$meses.no.orgao <- CalcMeses(df$dataOrgao)
df$meses.como.servidor <- CalcMeses(df$dataServico)
df$anos.no.cargo <- CalcAnos(df$dataCargo)
df$anos.no.orgao <- CalcAnos(df$dataOrgao)
df$anos.como.servidor <- CalcAnos(df$dataServico)Agora podemos começar a fazer algumas perguntas aos nossos dados:
1. Qual o tempo médio (em meses) dos servidores no Brasil?
ggplot(df, aes(x=anos.como.servidor)) +
geom_histogram(binwidth=1) +
scale_x_continuous(breaks=c(1, seq(5, max(df$anos.como.servidor, na.rm=T)+1, by=5))) +
theme_bw() +
labs(title = "Tempo em que os servidores federais estão trabalhando no Estado",
x = "Tempo no serviço público em anos", y = "Número de servidores")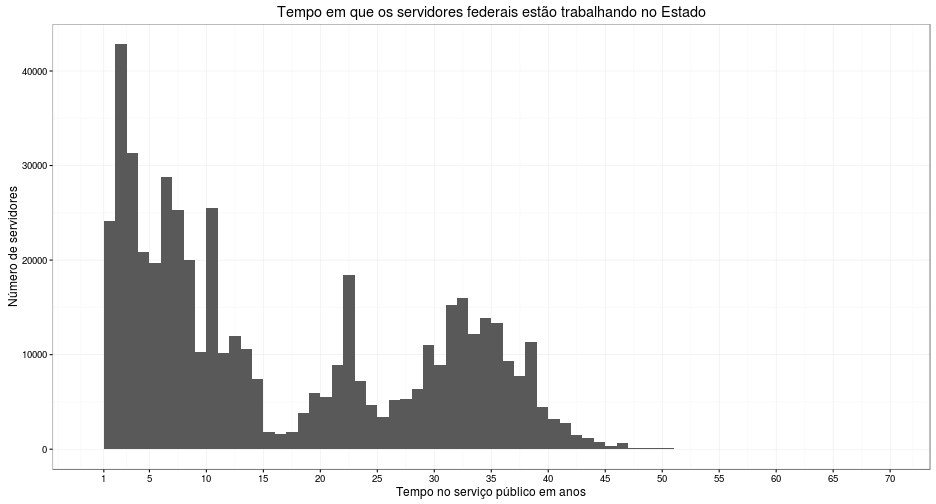
Observações:
- A maioria dos servidores tomou posse há 3 anos.
- Existe um número absurdamente grande de servidores com mais de 30 anos no serviço público. Na verdade, é mais comum encontrar um servidor que tenha mais de 30 anos de serviço do que entre 15 a 25.
- Existem alguns outliers que têm mais de 55 anos que causaram a distorção do histograma.
Separado por região e excluindo os outliers:
escala = c(1, seq(5, max(df$anos.como.servidor, na.rm=T)+1, by=5))
ggplot(subset(df, anos.como.servidor <= 50), aes(x=anos.como.servidor)) +
geom_histogram(binwidth=1) +
scale_x_continuous(breaks = escala) +
facet_grid(REGIAO~., scales="free") +
theme_bw() +
labs(title = "Tempo em que os servidores federais estão trabalhando no Estado",
x = "Tempo no serviço público em anos", y = "Número de servidores")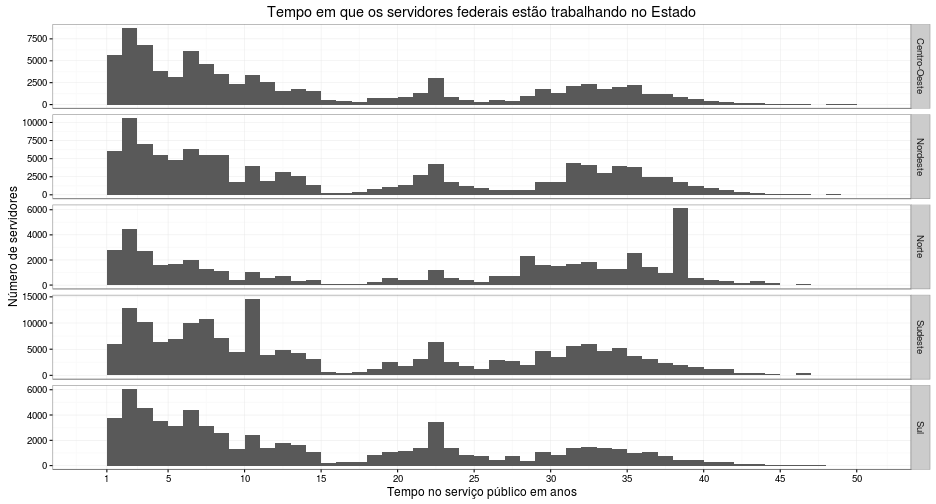
Fica muito fácil detectar a anomalia nos dados: o número de servidores que são funcionários do governo há mais de 35 anos na região Norte é assustador. São mais de 6000, muito mais do que em qualquer região. Na verdade, essa é a faixa de idade com mais pessoas dessa região.
Separado por região, mas mostrado por boxplots:
#Boxplot
# Regiões
ggplot(data=df, aes(x=REGIAO, y=anos.como.servidor, fill=REGIAO)) +
geom_boxplot() +
scale_fill_brewer(palette="Set1") +
guides(fill=FALSE) +
scale_y_continuous(breaks=escala) +
labs(title = "Distribuição do tempo no serviço público de acordo com a região", x = "Região", y = "Anos como servidor") +
theme_bw()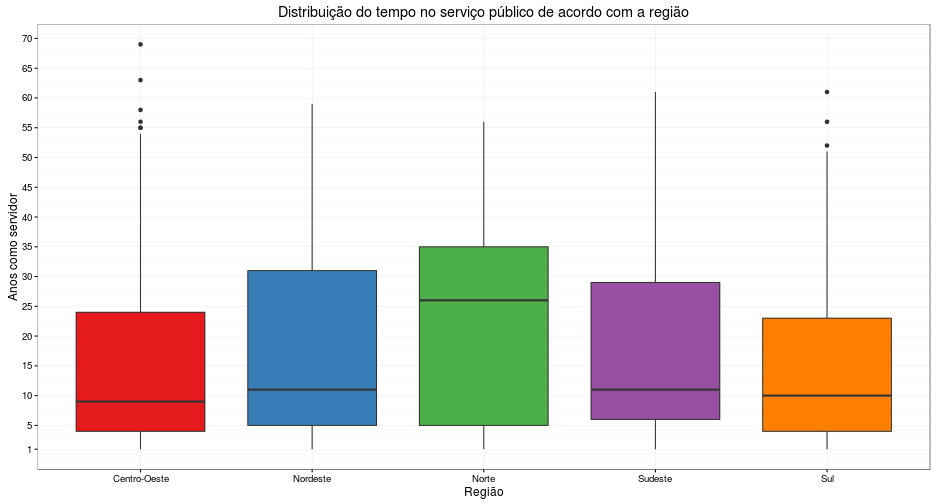
Depois do gráfico acima, acredito que não restam mais dúvidas que o Boxplot é uma ferramenta muito superior ao histograma quando o objetivo é comparar a distribuição de uma mesma variável numérica de acordo com outra variável categórica. Aqui, é muito mais fácil detectar que existe algo muito estranho no Norte: Os servidores de lá têm, em média, 25 anos de serviço público. A diferença para as outras regiões é colossal.
As diferenças ficam ainda mais gritantes quando se faz a estratificação por estado. A linha verde horizontal representa a mediana geral do tempo em que as pessoas do dataset estão trabalhando para o governo:
#: Agrupar estados por região
#Vetor de cores:
coresEstados <- c(
#Norte
"AM" = "#8dd3c7", "AP"="#ffffb3", "AC" = "#bebada",
"PA" = "#fb8072", "RO" = "#80b1d3", "RR" = "#fdb462",
#Nordeste
"AL" = "#8dd3c7", "BA" = "#ffffb3", "CE" = "#bebada",
"MA" = "#fb8072", "PB" = "#80b1d3", "PE" = "#fdb462",
"PI" = "#b3de69", "RN" = "#fccde5", "SE" = "#d9d9d9", "TO" = "#bc80bd",
#CO
"DF" = "#8dd3c7", "GO" = "#ffffb3", "MS" = "#bebada", "MT" = "#fb8072",
#SUDESTE
"SP" = "#8dd3c7", "RJ" = "#ffffb3", "ES" = "#bebada", "MG" = "#fb8072",
#SUL
"PR" = "#b3de69", "SC" = "#fccde5", "RS" = "#d9d9d9"
)
ggplot(data=df, aes(x=UF_EXERCICIO, y=anos.como.servidor, fill=UF_EXERCICIO)) +
geom_boxplot() +
facet_grid(. ~ REGIAO, scales="free") +
scale_y_continuous(breaks=escala) +
labs(title="Tempo médio dos servidores no\n funcionalismo público por estado", x="Estado", y="Tempo como servidor em anos") +
scale_fill_manual(values= coresEstados) +
guides(fill=FALSE) +
geom_hline(aes(yintercept = median(df$anos.como.servidor, na.rm = TRUE)), color = "green") +
theme(axis.text.x=element_text(angle=45)) +
theme_bw()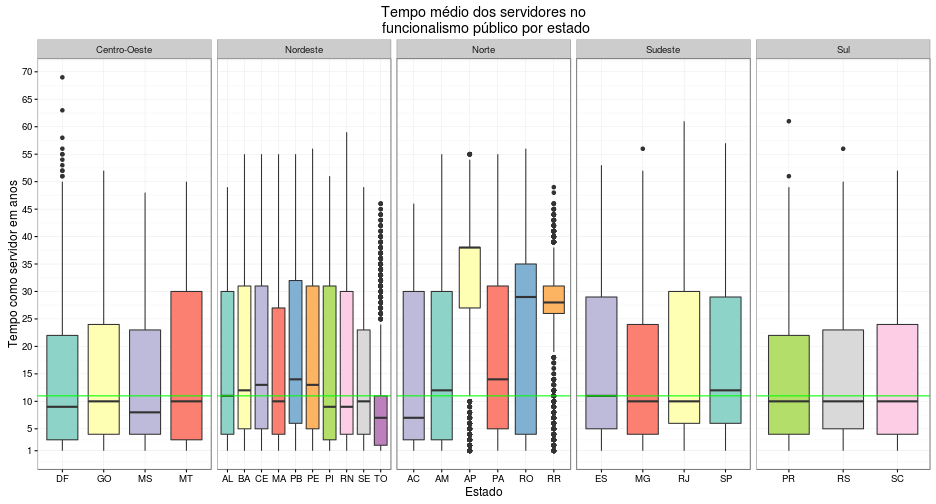
Parem e percebam o quão absurda é a situação em Amapá, que merece dois comentários a parte:
- A mediana é igual a cerca de 37 anos. Na verdade, a distribuição é tão bagunçada que a mediana deixa de fazer sentido aqui nesse contexto.
- Os servidores com menos de 11 anos, que é a mediana geral, são considerados anomalia no estado.
- Em comparação, Tocantins parece ser uma situação oposta ao estado do Norte.