Transparência (1): Qual estado brasileiro tem o maior número de servidores federais?
1 - Introdução
Alguns dos datasets brasileiros mais interessantes podem ser encontrados no Portal da Transparência, no qual é possível obter dados sobre:
- gastos diretos do Governo Federal (desde 2004 - exceto Cartão de Pagamentos - desde 2002)
- transferências de recursos a Estados e Municípios (desde 2004)
- convênios com pessoas físicas, jurídicas ou entes governamentais (desde 1996)
- previsão e arrecadação de receitas (desde 2009)
- servidores do Governo Federal.
É por esse último item que mais me interessei no momento e sobre o qual publicarei uma série de posts nos próximos dias.
Os dados foram baixados deste endereço e correspondem ao mês de Agosto, que era a opção mais recente disponível até então.
A pasta zipada baixada contém cinco arquivos, dentre os quais só usaremos dois: 20150831-Cadastro.csv e 20150831-Remuneracao.csv. Ambos contem 44 variáveis e cerca de 700 mil linhas, mais a maioria delas não são muito importantes neste contexto.
2. Importação e limpeza dos dados
Após carregar as bibliotecas que serão usadas, hora de carregar os dados. Essa foi a primeira vez que eu trabalhei com um dataset tão grande no R. O arquivo pesa mais de 370 MB e demorou mais de um minuto para ser carregado. Imagina se fosse no Excel..
Ao notar que o carregamento dos dados demorava muito, usei uma solução que aprendi em fóruns sobre o R: importar apenas as colunas necessárias usando dplyr. Menos da metade das colunas presentes no arquivo csv original serão usadas na análise e o ato de filtrá-las fora agiliza em muito a importação para o R. Confira a comparação:
# Teste 1: Importar tudo
system.time(df <- read.csv("C:/R/data/201508_Servidores/20150831_Cadastro.csv", sep="\t", stringsAsFactors = FALSE))## Warning in read.table(file = file, header = header, sep = sep, quote =
## quote, : line 2 appears to contain embedded nulls## Warning in read.table(file = file, header = header, sep = sep, quote =
## quote, : line 3 appears to contain embedded nulls## Warning in read.table(file = file, header = header, sep = sep, quote =
## quote, : line 4 appears to contain embedded nulls## Warning in read.table(file = file, header = header, sep = sep, quote =
## quote, : line 5 appears to contain embedded nulls## Warning in scan(file = file, what = what, sep = sep, quote = quote, dec =
## dec, : embedded nul(s) found in input## user system elapsed
## 42.68 0.70 43.93# Teste 2: importar apenas colunas importantes
system.time(df <- read.csv("C:/R/data/201508_Servidores/20150831_Cadastro.csv",
sep="\t", stringsAsFactors = FALSE) %>%
select(-DIPLOMA_INGRESSO_CARGOFUNCAO, -DATA_NOMEACAO_CARGOFUNCAO,
-REFERENCIA_CARGO, -COD_AFASTAMENTO, -COD_GRUPO_AFASTAMENTO,
-NIVEL_CARGO, -COD_UORG_EXERCICIO, -COD_UORG_LOTACAO, -OPCAO_PARCIAL,
-DIPLOMA_INGRESSO_SERVICOPUBLICO, -DIPLOMA_INGRESSO_ORGAO,
-DOCUMENTO_INGRESSO_SERVICOPUBLICO, -DATA_INICIO_AFASTAMENTO,
-DATA_TERMINO_AFASTAMENTO, -TIPO_VINCULO, -COD_ORGSUP_EXERCICIO,
-COD_ORG_EXERCICIO, -COD_ORGSUP_LOTACAO, -COD_ORG_LOTACAO,
-CPF, -MATRICULA, -FUNCAO, -CLASSE_CARGO, -PADRAO_CARGO,
-SIGLA_FUNCAO, -NIVEL_FUNCAO, -CODIGO_ATIVIDADE)
)## user system elapsed
## 37.34 0.56 38.31Cada linha do df corresponde a um servidor e cada uma das variáveis corresponde a um atributo do mesmo.
Primeiro ponto a ser analisado: qual a qualidade dos dados? Quantas variáveis tem muitos valores vazios ou nulos?
## Id_SERVIDOR_PORTAL NOME
## 0 0
## ORG_EXERCICIO ORGSUP_EXERCICIO
## 4 4
## SITUACAO_VINCULO REGIME_JURIDICO
## 4 4
## JORNADA_DE_TRABALHO DATA_DIPLOMA_INGRESSO_SERVICOPUBLICO
## 4 4
## ORG_LOTACAO ORGSUP_LOTACAO
## 14 14
## DATA_INGRESSO_ORGAO DATA_INGRESSO_CARGOFUNCAO
## 2799 47192
## UORG_LOTACAO DESCRICAO_CARGO
## 120819 154017
## UORG_EXERCICIO UF_EXERCICIO
## 165589 189437
## ATIVIDADE
## 688290Visto que é possível que um mesmo servidor tenha mais de um cargo público (por exemplo, uma pessoa pode ser professora de universidade federal e chefe de seu departamento), é necessário excluir os servidores repetidos.
length(df$Id_SERVIDOR_PORTAL) #Quantidade de IDs de servidores no arquivo## [1] 795107length(unique(df$Id_SERVIDOR_PORTAL)) #Quantidade de IDs únicas## [1] 681266100 * length(unique(df$Id_SERVIDOR_PORTAL)) / 605670 # Porcentual de IDs únicas## [1] 112.4814df <- df[!duplicated(df$Id_SERVIDOR_PORTAL), ]Uma informação não presente no relatório é a região do Servidor. Isso é facilmente inserido manualmente pelo R (aliás, um bom exercício seria a criação de uma library com datasets brasileiros).
UF_EXERCICIO = sort(unique(na.omit(df$UF_EXERCICIO)))
br <- data.frame(UF_EXERCICIO)
br$REGIAO <- c('Norte', 'Nordeste', 'Norte', 'Norte', 'Nordeste', 'Nordeste', 'Centro-Oeste', 'Sudeste', 'Centro-Oeste', 'Nordeste', 'Sudeste', 'Centro-Oeste', 'Centro-Oeste', 'Norte', 'Nordeste', 'Nordeste', 'Nordeste', 'Sul', 'Sudeste', 'Nordeste', 'Norte', 'Norte', 'Sul', 'Sul', 'Nordeste', 'Sudeste', 'Nordeste')
df <- merge(df, br, by="UF_EXERCICIO")Observação: notei um comportamento estranho do R. Ao fazer o merge(), ele automaticamente deleta todas as linhas onde o valor da variável UF_EXERCÍCIO é nulo. Como isso não implica um grande prejuízo para a análise, iremos proseguir mesmo assim.
Vamos agora à exploração básica de dados. Primeira pergunta: qual estado tem o maior número de servidores públicos?
temp <- df %>%
select(UF_EXERCICIO, REGIAO) %>%
mutate(Estado = UF_EXERCICIO) %>%
group_by(Estado, REGIAO) %>%
summarise(numero.servidores = n())
ggplot(data=temp, aes(x=reorder(Estado, numero.servidores), y=numero.servidores, fill=REGIAO)) +
geom_bar(stat="identity") + coord_flip() +
labs(title="Número de servidores por Estado", x="", y="Número de servidores") +
theme_economist() +
scale_fill_economist()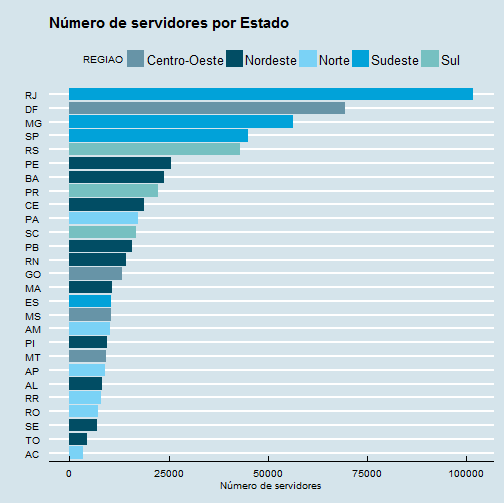
#Gráfico por região
df %>%
select(REGIAO) %>%
group_by(REGIAO) %>%
summarise(numero.servidores = n()) %>%
ggplot(aes(x=reorder(REGIAO, numero.servidores) , y=numero.servidores)) +
geom_bar(stat="identity") + coord_flip() +
labs(title="Número de servidores por Estado", x="", y="Número de servidores") +
theme_economist()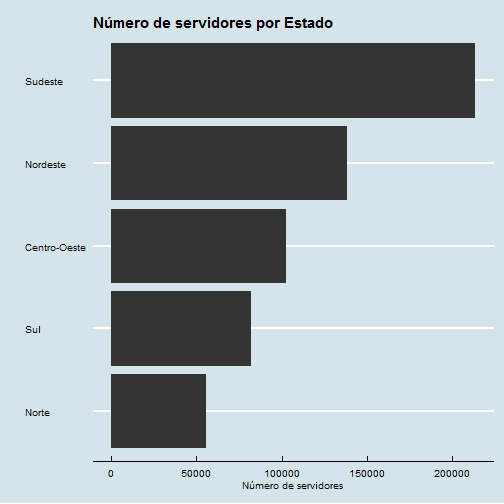
É claro que a população de cada estado tem uma grande influência no resultado anterior… será? Para tirar a dúvida, aqui vai um gráfico de proporção de servidores em cada estado. A tabela com a população de cada estado foi extraída manualmente da Wikipedia.
pop <- read.csv2("C:/R/data/201508_Servidores/populacao.csv", stringsAsFactors = FALSE)
names(pop) <- c("Estado", "População")
temp <- merge(temp, pop, by="Estado")
temp$Proporcao = round(1000*(temp$numero.servidores/temp$População),2)
ggplot(data=temp, aes(x=reorder(Estado, temp$Proporcao), y=temp$Proporcao, fill=REGIAO)) +
geom_bar(stat="identity") + coord_flip() +
labs(title="Proporção de servidores por Estado", x="Estado", y="Proporção da população \n que é funcionário público") +
theme_economist()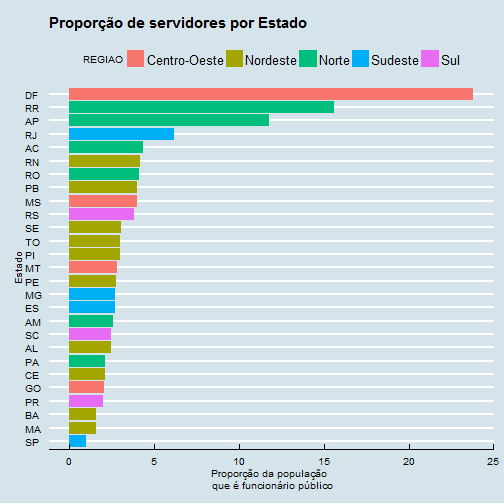
Os resultados são muito interessantes. Mais de um quarto dos habitantes do Distrito Federal são funcionários públicos. Roraima, Amapá e Rio de Janeiro também parecem ter máquinas públicas inchadas.
Para finalizar, vou salvar o data frame criado para posteriores análises.
df %>% as.data.frame() %>% write.csv2(file = "C:/R/data/201508_Servidores/transparencia.csv", row.names = FALSE)O novo arquivo tem 191 MB, 48% a menos que o original.